I have managed to put together the following method in order to retrieve both CSV and “Anonymous XML” reports from a completed report:
def get_report(gmp: Gmp, report_id, file_name):
# First, find the right report ID
resp = gmp.get_report_formats()
report_formats = resp.xpath("//report_format") # [-1].xpath("@id")
report_format_id = False
extension = ""
for f in report_formats:
save_file = False
if f.xpath(".//name")[1].text == "CSV Results":
report_format_id = f.xpath("@id")[0]
save_file = True
extension = "csv"
elif f.xpath(".//name")[1].text == "XML":
report_format_id = f.xpath("@id")[0]
save_file = True
extension = "xml"
# Print the data and/or add it to a file
resp = gmp.get_report(report_id, report_format_id=report_format_id, ignore_pagination=True)
if save_file == True:
if extension == "csv":
f = open("{}.{}".format(file_name, extension), "wb")
csv_in_b64 = resp.xpath('report/text()')[0]
csv = base64.b64decode(csv_in_b64)
f.write(csv)
f.close()
if extension == "xml":
f = open("{}.{}".format(file_name, extension), "w")
resp = gmp.get_report(report_id, report_format_id=report_format_id, ignore_pagination=True)
data = print_pretty_xml(resp)
f.write(data)
f.close()
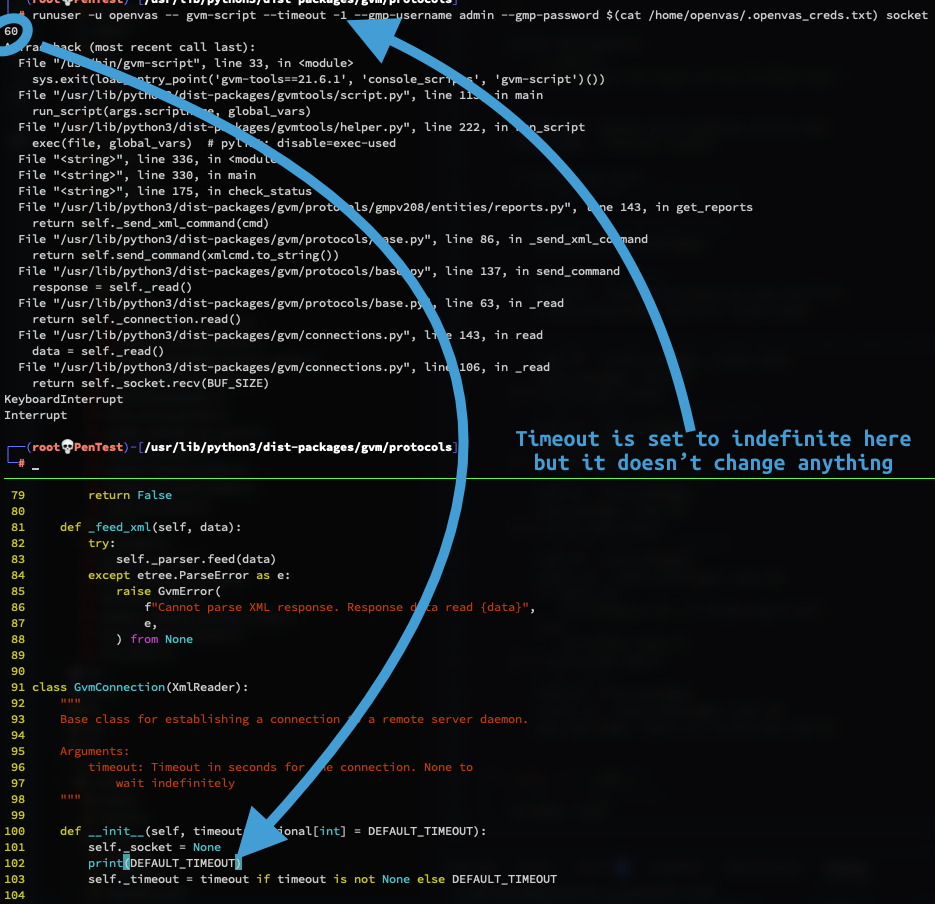
This works perfectly fine for smaller reports, but this fails miserably on larger reports. I have a report that has a lot of findings, resulting in a 1.1MB CSV and a 22MB XML file when exported manually. However, when trying to run the script and ignore pagination, it just fails with a timed out error message.
└─# time runuser -u openvas -- gvm-script --gmp-username admin --gmp-password $(cat /home/openvas/.openvas_creds.txt) socket /home/openvas/gvm-script.py --report /home/openvas/openvas-20a4d0cfc753-1424
Timeout while reading the response
real 1m2.808s
user 0m0.337s
sys 0m0.052s
As you can see from above, it waits like a minute or so before it times out. Is there any way that I can just simply increase the timeout window, or is there an “easy” way to implement retrieving the report contents using pagination? I noticed that all of the python gvm-scripts on GitHub ignore pagination, so I’m not sure what this would look like if pagination wasn’t ignored.